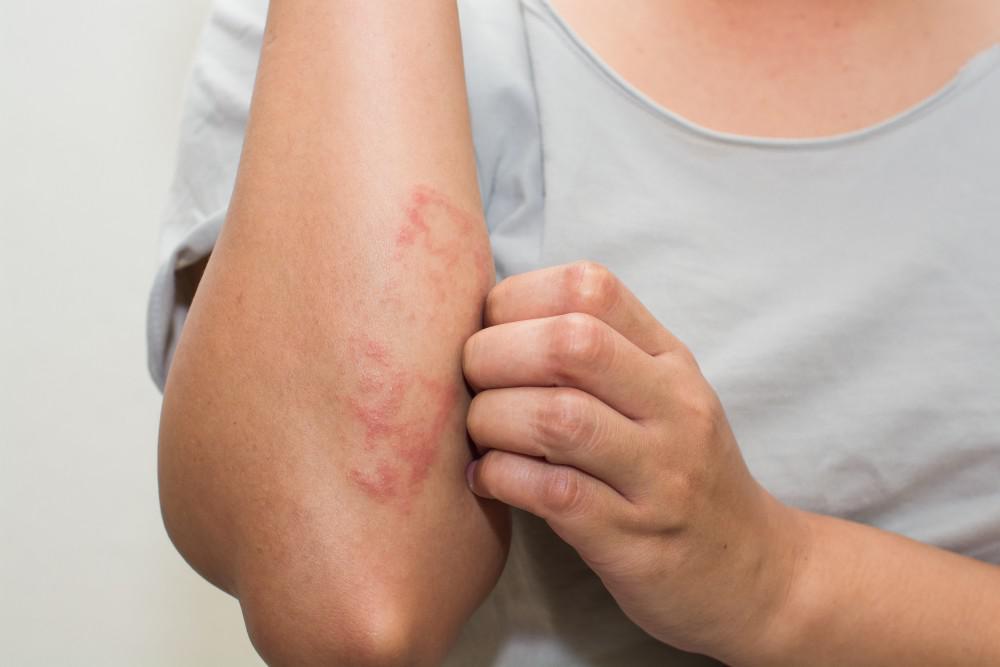
Die erste Frage, die Ihnen zum Thema Ekzeme wahrscheinlich in den Sinn kommt, ist: „Was genau ist das?“ Und der zweite – „Ist Ekzeme ansteckend?“
Ekzem ist eine Hauterkrankung, die durch chronisches oder anhaltendes Auftreten von Hautausschlägen, Hautschwellungen, Rötungen, Juckreiz und Trockenheit gekennzeichnet ist. Es ist auch nicht ungewöhnlich, dass Läsionen und Blasenbildung auftreten. Es ist ratsam, diese Ausschläge nicht zu zerkratzen, da dies zu Infektionen und einer weiteren Verschlechterung des Hautzustands führen kann.
Es ist eine ziemlich häufige Hauterkrankung. Bei fast 10 % der Weltbevölkerung wurde einmal im Leben ein Ekzem diagnostiziert. Unter den dermatologischen Beschwerden, die von Hautärzten beobachtet werden, sind 15-25% davon einige Arten von Ekzemen.
Bei dieser Prävalenz fragen Sie sich vielleicht, ob Ekzeme ansteckend sind? Die Antwort ist nein. Ekzem ist eine nicht ansteckende Hautkrankheit, die im Allgemeinen genetisch bedingt ist und ein wenig durch Umweltfaktoren beeinflusst werden kann.
Wie bereits erwähnt, gibt es verschiedene Arten von Ekzemen. Es kann nach seiner Prävalenz, nach dem Körperteil, an dem es aufgetreten ist (Handekzem usw.), nach seinem Aussehen oder nach der Ursache klassifiziert werden. Um einfach die gebräuchlichste Klassifikation zu nennen, sind im Folgenden die Arten der Bedingung basierend auf ihrer Häufigkeit aufgeführt.
Es gibt zwei Arten unter dieser Klassifizierung – die eine sind die häufigen Arten von Ekzemen und die andere sind natürlich die weniger häufigen.
Unter den allgemeinen Typen sind:
ein. Atopisches Ekzem oder atopische Dermatitis – ist eine allergische Reaktion, die bei Familien mit Asthma in der Vorgeschichte allgemein als genetisch bedingt angesehen wird
b. Kontaktdermatitis – ist eine Reizung, die entweder durch ein Allergen oder durch einen Reizstoff verursacht wird. Es kann behandelt und verhindert werden, da die zugrunde liegende Ursache vollständig aus der Umgebung des Patienten entfernt werden sollte
c. Xerotisches Ekzem – es ist ein Ekzem, das sich aus einer Verschlimmerung trockener Haut entwickelt hat. Die Trockenheit war so stark, dass sie sich zu einer härteren Form entwickelt hat. Fälle treten im Winter häufiger auf
d. Seborrhoische Dermatitis – auch Milchschorf genannt. Es ist eine Erkrankung, die häufig Neugeborene betrifft. Es ist eng mit Schuppen verwandt.
Unter den weniger verbreiteten Typen sind:
ein. Dyshidrose – eine Art von Dermatitis, die auch als Hausfrauenekzem bezeichnet wird. Dieser Typ findet sich häufig an Handflächen, Fußsohlen, Fingern und Zehen. Es ist auch eng mit dem Handekzem verwandt. Im Gegensatz zu anderen Arten verschlechtert es sich im Sommer oder bei heißem Wetter.
b. Diskoides Ekzem – dies sind ovale Läsionen und werden auch nummuläre Dermatitis genannt, was auf Latein „geprägt geformt“ bedeutet
c. Venöse Dermatitis oder Stauungsdermatitis – häufig an Beinen mit Durchblutungsstörungen
d. Neurodermitis oder Lichen simplex chronicus – ein Zustand, der durch gewohnheitsmäßiges oder zwanghaftes Kratzen aufgrund von chronischem Juckreiz verursacht wird, der zu einer Verdickung der Haut führt.
e. Autoekzematisierung – es ist eine Hauterkrankung, die aus einer Infektion durch Parasiten, Viren, Bakterien oder Pilze resultiert.
Die Kenntnis dieser Typen kann dem Betroffenen helfen, die vorbeugenden Maßnahmen zu bestimmen, die er ergreifen muss. Wenn Sie glauben, an einem der genannten Symptome zu leiden, ist es dennoch am besten, Ihren Dermatologen zu konsultieren, um den besten und sichersten medizinischen Rat zu erhalten. Ärzte sind immer noch die glaubwürdigsten Personen, um Ihre medizinischen Fragen zu beantworten, wie „Ist Ekzeme ansteckend?“ und andere.
Inspiriert von Veronica Ayuste